
Quando um site não aparece bem no Google, muita gente pensa logo em conteúdo, anúncios ou palavras-chave.
Mas, às vezes, o problema está em um arquivo pequeno e quase invisível: o robots.txt.
Além disso, esse arquivo faz parte do SEO técnico e pode influenciar a forma como os robôs de busca acessam o seu site.
Para que serve o robots.txt?
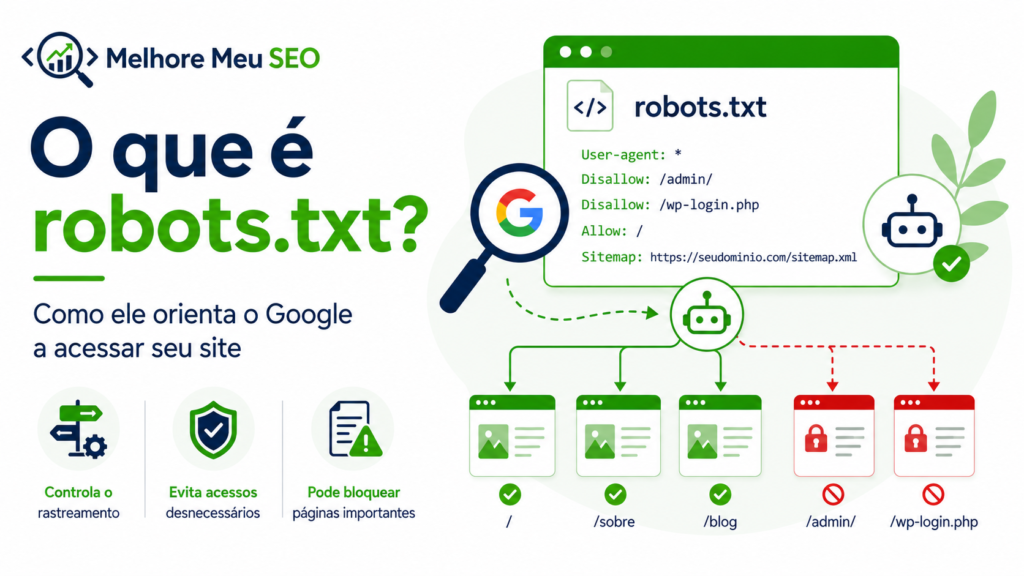
O robots.txt orienta os robôs dos mecanismos de busca sobre quais partes do site eles podem acessar.
Normalmente, ele fica na raiz do domínio, em um endereço como:
seudominio.com.br/robots.txt
Na prática, ele funciona como uma placa de orientação para os rastreadores.
Ele pode indicar, por exemplo:
- quais áreas do site não precisam ser acessadas;
- quais diretórios devem ser evitados;
- onde está o sitemap;
- quais regras se aplicam aos robôs de busca.
Por isso, esse arquivo ajuda a organizar o rastreamento, principalmente em sites maiores ou com muitas páginas.
Como ele funciona?
Quando o Googlebot chega em um site, ele pode consultar o robots.txt antes de rastrear algumas URLs.
Se encontrar uma regra de bloqueio, ele evita acessar aquela parte do site.
Em alguns casos, isso pode ser útil para áreas internas, páginas sem importância para busca ou URLs técnicas que não precisam aparecer no rastreamento.
Por exemplo, um site pode bloquear:
- páginas administrativas;
- filtros de busca;
- parâmetros de URL;
- arquivos internos;
- áreas de teste;
- resultados de pesquisa interna.
No entanto, o problema começa quando uma regra bloqueia algo importante por engano.
Robots.txt remove página do Google?
Não exatamente.
Na verdade, essa é uma confusão muito comum.
O robots.txt pode bloquear o acesso dos robôs a uma página, mas isso não significa que a página será removida automaticamente do Google.
Para impedir que uma página apareça nos resultados de busca, geralmente o caminho correto é usar noindex ou proteger a página com senha, dependendo do caso.
Ou seja:
- robots.txt controla rastreamento;
- noindex controla indexação;
- senha bloqueia o acesso real à página.
Por isso, misturar essas funções pode causar problemas sérios no SEO.
Como esse arquivo pode prejudicar o SEO?
Além disso, um robots.txt mal configurado pode impedir que o Google acesse partes importantes do site.
Isso pode afetar:
- páginas de serviços;
- posts do blog;
- páginas de produtos;
- categorias;
- imagens;
- arquivos CSS;
- arquivos JavaScript;
- páginas comerciais importantes.
Quando o Google não consegue acessar uma parte essencial do site, ele pode ter dificuldade para entender o conteúdo corretamente.
Em alguns casos, páginas importantes podem perder força ou demorar mais para aparecer nos resultados.
Exemplo de erro comum
Um erro perigoso é bloquear o site inteiro sem perceber.
Veja este exemplo:
Disallow: /
Essa regra pode impedir os robôs de acessarem todo o site.
Em ambiente de teste, isso até pode fazer sentido. Mas, em um site publicado, vira um problemão.
É aquele detalhe pequeno que parece inofensivo, mas deixa o Google do lado de fora olhando pela janela.
SEO técnico tem dessas: um comando errado e pronto, o site começa a brincar de esconde-esconde.
Todo site precisa ter robots.txt?
Nem todo site precisa de regras complexas.
Um site pequeno pode ter um robots.txt simples, apenas com a indicação do sitemap e sem bloqueios desnecessários.
Mesmo assim, o mais importante é garantir que ele não bloqueie páginas essenciais para o negócio.
Um bom robots.txt não precisa ser cheio de comandos. Ele precisa ser claro, limpo e correto.
Como saber se meu robots.txt está certo?
Você pode começar acessando:
seudominio.com.br/robots.txt
Depois, observe se existe alguma regra bloqueando áreas importantes.
Alguns sinais de alerta são:
Disallow: /;- bloqueio de
/blog/; - bloqueio de páginas de serviço;
- bloqueio de arquivos importantes;
- regras antigas deixadas após uma reformulação;
- diferença entre o site de teste e o site publicado.
Também vale conferir o Google Search Console para ver se há problemas de rastreamento ou indexação.
Se o seu site não aparece bem nos resultados, veja também o artigo sobre como saber se meu site aparece no Google.
Robots.txt e sitemap trabalham juntos?
Sim.
É comum o robots.txt indicar onde está o sitemap do site.
Exemplo:
Sitemap: https://seudominio.com.br/sitemap.xml
Isso ajuda os mecanismos de busca a encontrarem o mapa com as URLs importantes.
Mas cada recurso tem uma função diferente:
- o sitemap mostra caminhos importantes;
- o robots.txt orienta o que pode ou não ser acessado;
- o noindex indica o que não deve ser indexado.
Quando esses elementos trabalham juntos do jeito certo, o Google entende melhor o site.
Quando revisar esse arquivo?
Vale revisar o robots.txt em algumas situações:
- depois de lançar um site novo;
- após uma reformulação;
- quando trocar de domínio;
- depois de instalar plugins de SEO;
- quando páginas importantes não aparecem no Google;
- quando o Search Console mostra erros;
- antes de publicar um site que estava em ambiente de teste.
Por fim, essa revisão evita bloqueios acidentais e ajuda a manter o rastreamento mais organizado.
Conclusão
O robots.txt é um arquivo simples, mas pode impactar bastante o SEO de um site.
Quando está correto, ele ajuda a orientar os robôs de busca. Quando está errado, pode impedir o Google de acessar páginas importantes.
Por isso, se o seu site não aparece bem no Google, vale conferir se o robots.txt não está bloqueando algo que deveria estar liberado.
Às vezes, o problema não é falta de conteúdo. É uma porta fechada que ninguém percebeu.
Quer saber se o Google consegue acessar corretamente o seu site? Faça uma análise técnica e descubra se o robots.txt está configurado do jeito certo.
Solicite uma análise inicial e entenda o que pode ser corrigido para melhorar sua presença orgânica.
Solicitar análise inicial